CS8803 OMSCS - GPU hardware and software
Overall review
This course was released in Spring 2024, and I decided to take this course instead of Software development process, along with Machine Learning. Ironically, I did not expect myself to take another C course.
Overall, I learnt quite a few things:
- With the most useful (and main reason) being able to program and understand the workings of CUDA and
- The internal working of a GPU, like what is a core in gpu context, how are threads and blocks organized,
- How do cache systems in a GPU work,
- How do we think about parallelism at a gpu level
- They also cover a few other things and provide quite a few papers to read (which you are being evaluated on).
Generally, I would not recommend the course if you are new to C and computing architectures/systems, I am thankful I took Graduate Introduction To Operating Systems as it covers things like makefile, segmentation fault, debugging in C, pointers, etc. Otherwise, I am positive I would not have done well. There was also a wide range of students who have taken HPCA, HPC, SAT and they basically cruise through the entire course, so, your mileage may vary, some folks will find it super easy and light weighted, while some students struggle significantly (like me?).
In addition, if your goal is specifically learning about GPU with accelerated computing (such as machine learning), perhaps consider taking this course in the future. The professor did ask for feedback and GPU with ML was one of the top occuring feedback on what projects students wished to see; and subsequently has offered to work with the spring 2024 batch of students as part of [CS 8903 - Special Problems] to come up with something for future semesters.
Also, TAs for this course are currently on campus PHD students / post doc, and quite a refreshing change as compared to other modules - they were really helpful, receptive to feedback, and willing to host individual office hours! Not to mention one of them were even an Nvidia software engineering intern and really knowledgable; they were also helpful and generous with hints during office hours!
Time & System Requirements
Given my background, I would say roughly about 10 hours per week, which definitely puts this course on the lower end of the spectrum. However, this is the first release of the course, there is a wide consensus that they will merge existing project 3 and 4 to one project (under GPU simulation), and project 5 was quite tough as they cover assembly knowledge / software analysis. I will mention more about this in the assignments section.
For the system requirements, you will be provided access to the PACE cluster (which is definitely required for A1 and A2), which requires Gatech VPN to login; if you only have a laptop/pc that forbids external software installation (such a corporate laptop) then this might be an issue.
Lectures and Quizzes
There are a total of 12 modules (with 12 quizzies), the content is as follows:
| Module | Description |
|---|---|
| Module 1 |
Introduction of GPU Instructor and Course Introduction Modern Processor Paradigms How to Write Parallel Programs Introduction to GPU Architecture History Trend of GPU Architechtures |
| Module 2 |
Parallel Programming Parallel Programming Patterns Open MP vs. MPI Programming with MPI |
| Module 3 |
GPU Programming Introduction Introduction of CUDA Programming Occupancy Host Code Stencil Operation with CUDA |
| Module 4 |
GPU Architecture Multi-threaded Architecture Bank Conflicts GPU Architecture Pipeline Global Memory Coalescing |
| Module 5 | Advanced GPU Programming |
| Module 6 |
GPU Architecture Optimizations I Handling Divergent Branch Register Optimizations Unified Register File and Shared Memory |
| Module 7 |
GPU Architecture Optimizations II GPU Virtual Memory UVA GPU Warp Scheduling |
| Module 8 |
GPU Simulation GPU Cycle Level Simulation Analytical Models of GPUs Accelerating GPU Simulation |
| Module 9 |
Multi-GPU Multi-GPU Hardware Concurrency on GPUs |
| Module 10 |
Compiler Background - I GPU Compiler Flow PTX IR and Basic Block Introduction to Data Flow Analysis Example of Reaching Definitions |
| Module 11 |
Compiler Background - II Live-Variable Analysis SSA Examples of Compiler Optimizations Divergence Analysis |
| Module 12 |
ML Accelerations On GPUs GPU and ML Floating Point Formats Tensor Core |
There are lecture slides provided, and each week you should not spend more than 2hours on watching the videos; that being said the lectures touches the surface level and they tend to be quite verbose (reading from lecture slides), so you may need to do a lot more self reading to fully grasp the content.
For more information and specifics (such as required readings), you can refer to my own GPU notes!
Grades Distribution
During my semester, the grades were distributed as follows - but as per my understanding this has already changed for Summer 2024, refer to the latest syllabus over here.
| Grading | |
|---|---|
| Quizzes (1-12) | 10% |
| Assignment 1 | 10% |
| Assignment 2 | 20% (With 5% EC) |
| Assignment 3 | 25% |
| Assignment 4 | 25% |
| Assignment 5 Or Final Exam |
10% |
For the Quizzes, you have two attempts where the latest attempt will be taken as your final score. Some of them can be quite tricky, especially if they are multiple choice multiple answer (MCMA) format. For Quizzies 6-9, there are significantly longer and they will test you on paper readings. IMO I did not really enjoy them, It sounds like “here, read it yourself and here is a bunch of follow up questions”, so, your milage may vary.
Assignment 3 was suppose to be a GPU simulator project, the original syllabus indicated that project 4 was supposed to be a compiler analysis project, but it ended up with 3 & 4 being a simulator project, and released a new optional project 5 on compiler analysis, where it can replace your final exam grade (better of the two).
Assignments
For Assignments 1 & 2, you definitely need access to a NVIDIA GPU, and for assignment 2, you will need to use a GPU from the PACE cluster to evaluate your performance. There is no gradescope available but code is provided to tell you if you are on the right track. Doing locally is possible but you will need to know how to setup your own gpu with cuda installed. For what it is worth, I did everything locally before testing it in the PACE cluster. If you are interested to know more about my setup, please refer to my post on setting up your deep learning rig.
For Assignments 3-5, there is feedback from gradescope and logging in to PACE is not required, I did everything locally.
Do spent time to understand the PACE cluster, there is actually a file system built in that allows you to edit your files easily. Initially I was using
nanoand pasting my scripts there and as expected, incredibly painful.
Assignments 1-4 is done in c++, while assignment 5 is done in python
!
Assignment 1 - Matrix Multiplication!
The first assignment is to implement a distributed matrix multiplication using a tiled method. That is, suppose you have two 1024 by 1024 matrix and you need to multiply them together, you need to split them each of them up into multiple tiles (say 4 by 4), and “combine/distribute” it such a way to do your matrix in parallel. This assignment is quite straight forward, and is intended for you to get used to the PACE cluster and class setup. (In summer 2024, the weightage dropped from 10% to 5%)
You will also see the comparision / speed up of running this matrix muplication with cuda, verus a native implementation with C++.
I found the following resources and youtube links very useful:
- Explaining Tiled matrix muplication by penny xu
- Illinois at Urbana-Champaign CSE408 - Applied Parallel Programming
And these following youtube videos as well:
Assignment 2 - Sorting!
In assignment 2, you are required to sort a 10 million sized array, and required to achieve a 45x speedup over the naive implementation, along with minimum benchmarks of occupancy and memory throughput. In layman terms, it means that you should be sorting that array, such that most of your threads + memory are in active usage, avoiding wastage while acheiving the required speedup.
 Sample bitonic sort, image from wikipedia
Sample bitonic sort, image from wikipedia
The assignment first asks you to use bitonic sort, as a way to implement parallel sorting algorithm (again, this is why I mention that your background really matters in this module), and after achieving it, you are free to explore other forms of speedup to achieve a 60x speedup for extra credit:
In addition, the HPC videos was incredibly useful, and (finally could) figured out what is required after watching it.
- The HPC site can be found here which will direct you to edstem here
- Focus on Comparison-Based Sorting
- Distributed Memory Sorting
During my local testing, I managed to get 76x speedup; the TA recorded a 73x speedup and apparently was the highest in class! ![]()
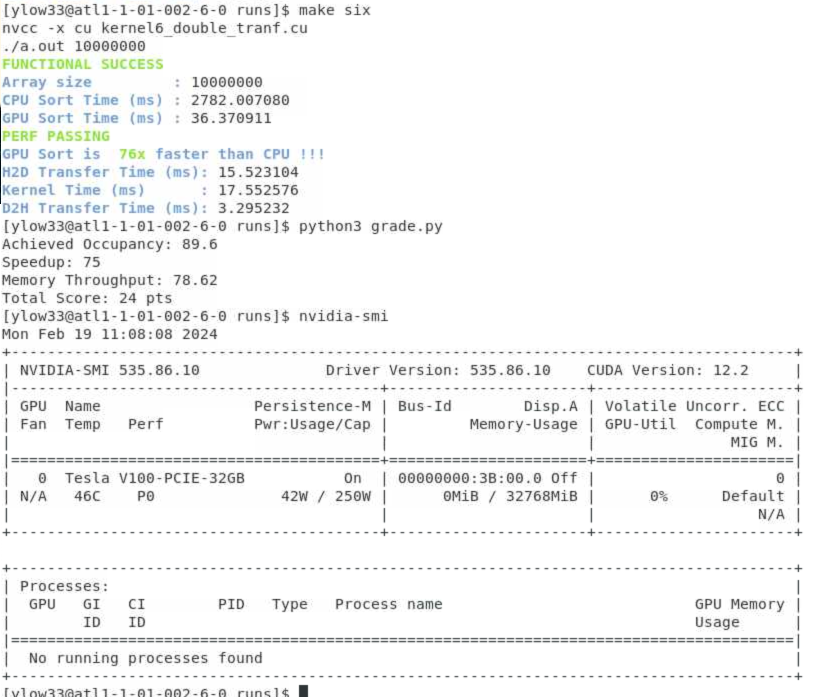 My PACE cluster terminal output
My PACE cluster terminal output
The benchmark is against a GPU type defined by the TA; this is why you need to access to the cluster to test it with that specific GPU specifcation! As shown, for my semester the benchmark / evaluation was done with a V100 GPU!
Assignment 3 & 4 - GPU simulation!
Assignment 3 and 4 are fairly related (and my belief that this will be combined as one project in the future). The project basically simulates some gpu instructions via a trace file based on certain characteristics.
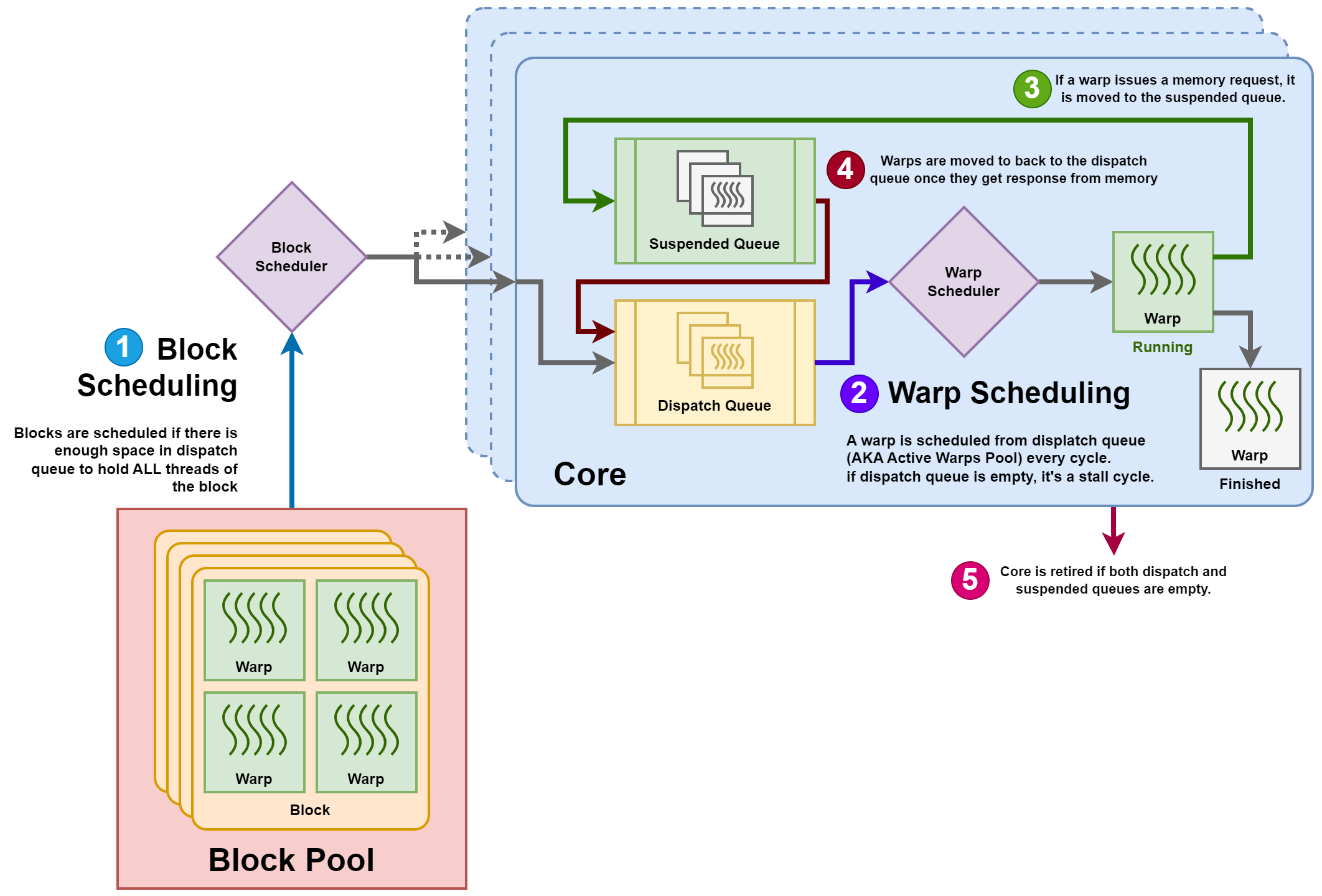
In Assignment3, they require you to implement 2 different scheduling strategies. The baseline strategy that is provided is a round robin strategy, and you will be required to implement:
- A
Greedy then Oldest (GTO)strategy, where the scheduler picks the same “task” until there is a long latency event, - A
Cache-Conscious Wavefront Schedulingwhich is based on one of the paper readings, focusing on L1 and L2 caches.
In assignment 4, you will study the difference between a compute core and tensor core by varying the execution width and tensor latency, and try to understand the various impact of various scheduling strategies when it comes to these. The tensor core is generally more suitable for matrix multiplication operations, particularly in artificial intelligence computations.
Assignment 5 - Warp Branch Divergence Detection
When it comes to “parallel algorthims”, detection of divergence becomes important - Ideally, you want instructions to be as homogenous as possible in a parallel seting. This project is about looking at the trace file, and detecting where such divergence instructions can occur.
Some folks who took Software Analysis and Testing (SAT) also found this to be easy while I found project 5 to be the hardest of them all ![]() . Thankfully this project only weighted 10% this semester, while for summer 2024 its 20%. So, lucky for being the pioneer batch.
. Thankfully this project only weighted 10% this semester, while for summer 2024 its 20%. So, lucky for being the pioneer batch.
Some folks suggested watching the dataflow analysis from SAT omscs videos to understand better.
Assignment Conclusion
Overall, for assignment 3,4,5 I felt the major challenge was trying to understand the code base rather than the underlying concepts, each assignment required less than 100 lines of code change once you understood what is required. Also, the assignment lack unit tests, and they evaluate based on the final output based on a set of metrics (like number of cycles). Some students “complained” that it seems more like reverse engineering the TA output in order for the exact match rather than the underlying concepts; which I somewhat agree. Again, this is the first semester being offered and I highly anticipate that this will change.
In constrast, I enjoyed assignment 2 the most, it was really fun trying to achieve the speedup and trying to squeeze every single inch of performance out, and understanding the internals of a cuda kernel. It was really fun to think about distributed sorting and matrix multiplication!
Final Exam
The final exam has 11 questions and is proctored, but by then I am just so tired, and I knew I had enough to secure an A, so I skipped the finals.
Additional Resources
There were alot of folks who suggested that HPCA was incredibly useful, so, I linked the notes over here; I did not have to refer them (nor have the time) for this course but leaving them here to whomever is interested: