CS7641 OMSCS - Machine Learning
Overall Review
If I had taken this as my first class (instead of 7/8 - sunk cost fallacy), I would have dropped out of OMSCS. I apologize in advance if this review seems negative, and it is not meant to bash or criticize the course in anyway.
Again, It’s always easier to be a critic than a creator!
With that out of the way, I took this course along with CS 8803 O21: GPU Hardware and Software as my 7th and 8th module of my 5th semester. This module is not about the algorithms or machine leraning, but the behavior of the machine learning algorithms based on the data. It is more of a “data science/analytics” course, where you are using existing tools (sklearn, pytorch), and trying to see the effects of each knob of each algorithm and how it interacts with the data. If you are taking this course and wish to do well, do check out other’s reviews as well as the assignments section.
For a little more context, The assignments is structured in an open ended way, and the rubrics is not disclosed but they do provide FAQs on what you need to include and those serves as a purpose. I will elaborate more on this in the assignments section.
Initially for A1, I “made a mistake (at least for the purpose of this course)” and focused too much on the algorithms, “stating” the findings on a superficial level and got 73. After I figured out what they really wanted, I got 100, 103 (98+5 extra credit) and 95 for the remaining assignments.
To understand what I meant by a “data science and analytics” course, do watch this youtube video featuring Professor Charles Isbell,Professor Michael Littmann and Lex Fridman, this link starts at a specific time, watch until 14.50. To be fair, I do witness in industry, where “(some) software engineers (or management)” think in a binary/simplistic way and unable able to be “flexible”; if this is the input, this should be the expected output - as though things are deterministic, but this is not the case for machine learning systems which has a strong dependency on your data. I have also been in conversations where engineers are discussing which algorithms to use, without even understanding how the data is collected or if the data is even being collected ![]() .
.
For this reason, coupled with the hidden rubrics, this course does give you quite a little bit (read: ALOT) of anxiety which I personally feel is unnecessary; how do you know whether you have done enough and “answer enough questions” and whether your answers are “interesting” enough? Which again, can be subjective.
Nonetheless, the course staff is trying very hard to make things better, for example in spring 2024 vs fall 2024, the professor removed midterms to help in student’s work life balance.
Starting in spring 2024, the TAs team also has been putting out blog articles to explain certain concepts.
Compared to times even prior to that (Prof Charles Isbell) the only way to get information was to attend office hours, now, TAs provides a “FAQ” section as a initial starting point and what you should include in your report.
They also allow chatGPT / generative AI in this class, which really helped!
Time requirements
I easily spend more than 20 hours per week on this assignment trying to think of “as many questions” and “comparisons” as I can. But I guess on hindsight, I could be less paranoid and spend lesser time while achieving the same grade.
Other(s) Reviews
- A fellow student’s review on this course by Nikhilkapila
- Another student’s review and survival guide by Anika Neela
- A reddit post: Why CS7641 is an awesome class and some tips to succeed.
Grades Distribution
| Type(Weightage) | Mean | Lower Quartile | Median | Upper Quartile | High |
|---|---|---|---|---|---|
| Assignment 1 (15%) | 70.74 | 58 | 74 | 85 | 105 |
| Assignment 2 (15%) | 67.51 | 53 | 72 | 86 | 105 |
| Assignment 3 (20%) | 62.54 | 51 | 64 | 78 | 105 |
| Assignment 4 (20%) | 67.64 | 56 | 72 | 84 | 105 |
| Final Exam (25%) | 37.59 | 35.22 | 39.35 | 43.65 | 53.3 |
| Reading Writing Quiz (5%) |
20.13 | 21.5 | 22 | 22 | 22 |
| Combined Grade | 69.01 | 61.92 | 71.93 | 79.91 | 97.53 |
There are also two extra credit opportunities, one for ed participation and one for attempting a problem set, intended to help you for the final exam.
The instructors do not release the cutoffs for A/B. However,
- There is a student who reported that he got an A with 69.5 (Not sure if its inclusive of Extra Credit)
- 53.11 resulted in a B (Again, not sure if its inclusive of Extra Credit)
- 49.975 resulted in a C.
Lectures
These are the lectures to watch for each week, they shouldn’t take you more than 3 hours each week:
-
SL: Supervised learning -
UL: Unsupervised learning (durh) -
RL: Reinforcement Learning
| Week 1 | SL 1 - Decision Trees |
| Week 2 | SL 2 - Regression & Classification SL 3 - Neural Networks |
| Week 3 | SL 4 - Instance Based Learning SL 5 - Ensemble Learning |
| Week 4 | SL 6 - Kernel Methods and SVMs |
| Week 5 | SL 7 - Computational Learning Theory SL 8 - VC Dimensions |
| Week 6 | SL 9 - Bayesian Learning SL 10 - Bayesian Inference |
| Week 7 | UL 1 - Randomized Optimization UL 5 - Information Theory |
| Week 9 | UL 2 - Clustering |
| Week 10 | UL 3 - Feature Selection UL 4 - Feature Transformation |
| Week 11 | RL 1 - Markov Decision Processes |
| Week 12 | RL 2 - Reinforcement Learning |
| Week 14 | RL 3, RL 4 - Game Theory |
There are also some assigned readings which I read none of them (GPU readings were significantly more interesting ahem).
In my opinion the lectures touch only the surface, and certain sections can be quite painful to watch. I suggest watching them at 2x speed and then finding your own resources to understand what is going on.
For example, I watched David Silver Lectures 1-4 to understand reinforcement learning. I also did not watch certain part of the lectures, and opt to just read from study guide(s) instead.
Useful Python Concepts
Do get additional computation resources, they will help you in your tuning and experiments. I am fortunate enough to have a powerful pc with 32 threads!
On top of that, spend time to understand the following concepts:
- Using joblib to distribute your code, this is especially important / useful for A2 and A4.
- Using Pickle to save/reload your results from your experiments - For me, I have a script to generate the results which ran overnight, and another script for analysis.
Quiz
There are some assigned readings that are meant for students to “learn” how to write better (at least in an academic setting). I… only attempted the quiz after assignment 4. There are unlimited attempts and the best score is taken.
Assignments
Do check out other’s reviews on how to do well, but the top 2 suggestions I have are following the FAQs and choosing an efficient report template. I will also try to provide my thought process on what made me do well for assignments 2-4.
Generally, on a very high level:
- Always ask yourself before you start any coding “what do you expect to see? and why?”
- If its possible, come up with a hypothesis and state it explicitly, ideally there should be some EDA involved to justify why your hypothesis is fair.
- Link back to the data/structure of the problem if its possible (more on this later), does the nature of the problem affects anything? What about the data?
- Always link back to lecture material or strongly grounded theory (Such as PCA is dependent on the variance of the data, so is bias towards features that have higher variance)
- Compare whenever/wherever you can and analyze them; for instance, model A perform than model B for this data, why? This data is more suitable for GMM instead of Kmeans, why?
FAQs
A fellow student remarked in ed discussions that (if you want to do well) you should follow the FAQs like a doctrine. If they ask or “casually” say you “should include” learning and validation curves, you are highly recommended to do so, else incur a huge penalty.
Report Templates
Use the IEEE latex for your assignments! Templates are already provided by KYLE NAKAMURA in his github, they really helped in saving space. In addition, I configure did my latex locally with vscode, so I could output my charts in my local file system and see real time changes to my report instead of constantly updating overleaf. Rendering is also significantly faster.
 IEEE template, double columns and being able to squeeze 2 images side by side!
IEEE template, double columns and being able to squeeze 2 images side by side!
In assignment 1, I made the mistake of combining my plots with matplotlib subplot. Starting from assignment 2 onwards, I just output all plots individually, mix & match based on what tells the most compelling story.
Datasets
Assignment 1
Supervised Learning
- Relevant Lectures: SL1-SL6
- Page limit: 10
In assignment 1, you are required to find two “interesting” datasets, and implement Decision Trees, Boosting, SVMs, Neural Network, and Knn. As much as possible during your assignment, try to make your functions modular, so you can re-generate your results with other datasets.
DO NOT use
pytorchand usesklearnif you can. (Yes, I know by usingsklearnit is hard to monitor log loss by epoch)You will understand why the moment you hit Assignment 2
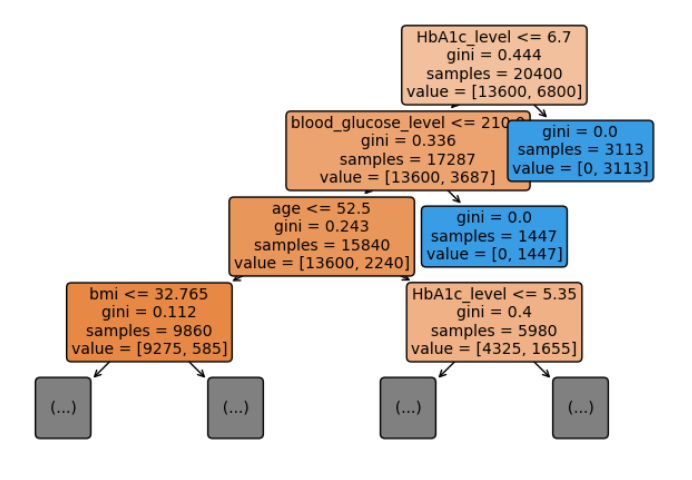 Visualization of one of my decision trees
Visualization of one of my decision trees
I made the initial mistake of describing all the different algorithms, such as saying decision tree interpretability is the highest, how the Svm kernel mathematically worked, how gradient vanishing plays a part; but as mentioned in overall review, none of that mattered. What is important is (in my opinion):
- Why does the validation curves show this?
- Why does model A better for dataset X instead of Y? And in contrast, why model B shows better performance for data Y instead of data X?
- How does each hyperparameter affect your dataset?
- How much of the performance is due to your dataset? For example, maybe your dataset is sparse? Or there is a feature leak? etc.
Assignment 2
Randomized algorithm
- Relevant Lectures: UL1
- Page limit: 10
- Requires the use of a custom library called mlrose
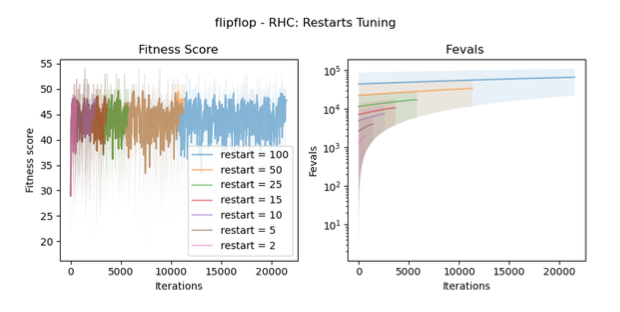 Random hill climbing for flipflop problem
Random hill climbing for flipflop problem
For Mimic, there is a fast_mode, you are strongly encouraged to use it.
1
2
3
4
problem = mlrose.DiscreteOpt(
length=size, fitness_fn=mlrose.FourPeaks(t_pct=t_pct), maximize=True
)
problem.set_mimic_fast_mode(fast_mode=True)
In assignment 2, you are required to find 3 different problems across 4 different “randomized optimization algorithm”, namely:
- Random Hill Climbing (RHC)
- Simulated annealing (SA)
- Genetic algorithm (GA)
- MIMIC
You are then required to use the RHC,SA,GA to train neural network weights.
After my feedback from A1, I actually wanted to drop this module, as I knew I was on the wrong track for A2. Thankfully, one of my friends motivated me to stay on.
So, I had no choice but to redo almost everything over the weekend.
So, in a nutshell, try to link back and talk about the data/nature of the problem as much as possible. In this assignment, convergence is key. For instance:
- As a starting point, based on your understanding on the algorithms, which problem is suited for which algorithm?
- Why is Knapsack Hard? Turns out it is because it is a NP-HARD problem
- How did you choose your convergence? Is there a closed form solution?
- Ok, you need to feature certain algorithms, is there a way to twig the problem size such that one problem performs a lot better?
- You wish to monitor convergence, is there a way to implement it? And why did you choose to implement it that way?
- Explain all your hyperparameters and show the effects, and why? With higher values of certain parameters, are you increasing exploitation or exploration?
- Do you expect SGD to have better performance over the other ROs? If so, why?
For this assignment, I wrote a lot of custom code including a state callback function.
Assignment 3
Unsupervised learning and dimensionality Reduction
- Relevant Lectures: UL2
- Page limit: 8
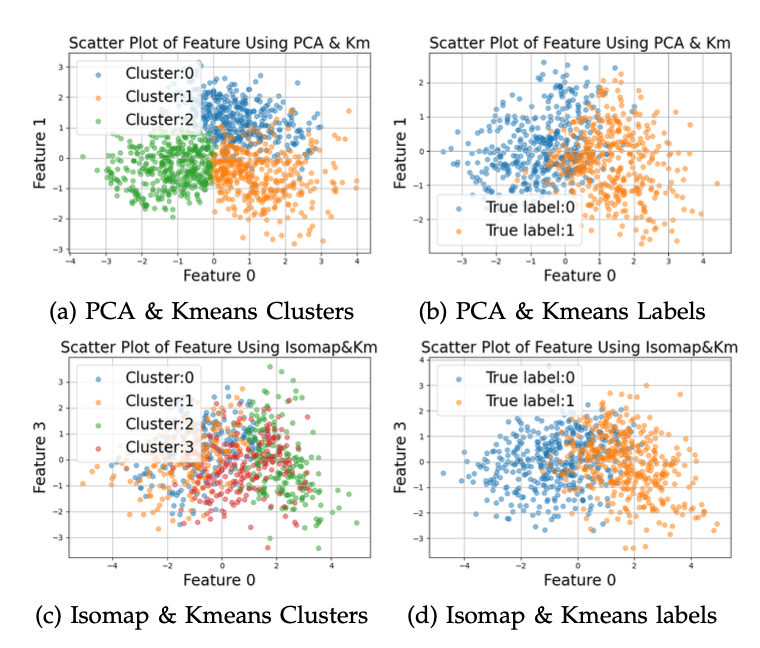 Visualization of my datasets after PCA/ISOmap with Kmeans
Visualization of my datasets after PCA/ISOmap with Kmeans
In assignment 3, you are required to run several dimensionality reduction algorithms, and then eventually re-run your neural network from part1 with clustering features. Again, the why is most important:
- Why do you get the following clustering assignments? Is the clustering assignment bias towards certain features? why?
- How do you compare the results after visualization?
- Why do you get these results? Can you map it back to the original features? (Yes, at least for PCA and ICA)
- Certain UL had a lousy performance, why?
- Compare every step with previous steps and compare, explain!
Overall, I compared whenever possible, and I plot all possible pair plots and choose the most interesting one to craft the most interesting story. In fact, for the neural network section, I changed my grid search and did some “seed engineering” in order to get the results that fit my hypothesis. cough.
Assignment 4
Reinforcement Learning
- Relevant Lectures: RL1-RL2
- Page limit: 8
- Requires the use of a custom library called bettermdptools
For assignment 4, you are required to find 2 mdp problems with one being non grid world and attempt to solve them with three different RL methods:
- Value iteration
- Policy iteration
- Q-learning
I just simply choose blackjack and frozen lake (simplest two), as I was pretty burnt out at this point.
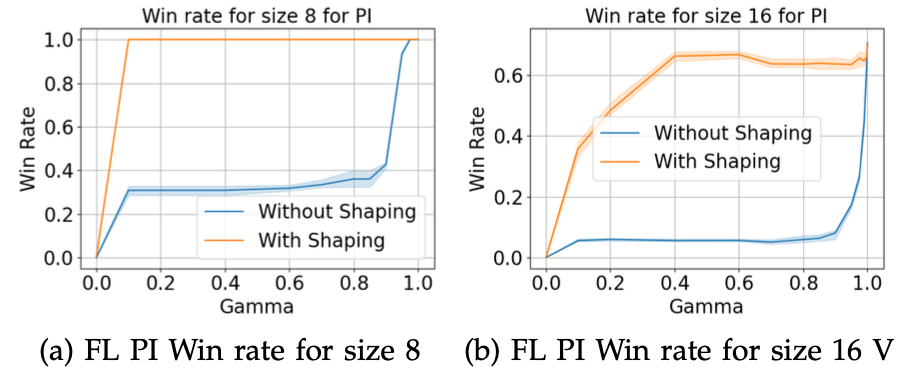 “Validation curves” for frozen lake with various parameters
“Validation curves” for frozen lake with various parameters
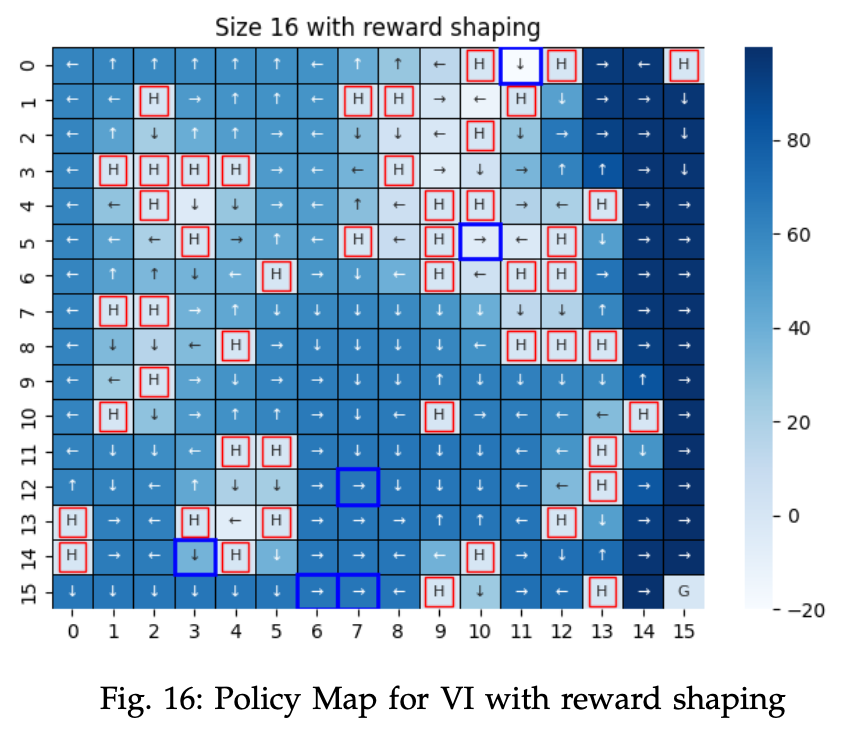 Policy learnt using RL for a 16 $\times$ 16 frozen lake problem
Policy learnt using RL for a 16 $\times$ 16 frozen lake problem
Again, come up with as many questions/why and explore as many things as you can:
- How did the size of the problem affect the algorithm? Do you see differing behavior? why?
- How VI/PI/QL number of iterations differ? What about the wall time?
- How do you think about convergence? How are you sure that the model has converged?
- Does certain problems prefer exploration and exploitation? Why? Can you prove it?
- Are the policies learnt different? Does Value and Policy iteration give the same answer? If not, why?
- What about Q-learning? Are there limitations of it? If so, Why? How did you overcome them?
Similarly I also did some “seed engineering” to get a decent frozen lake problem where I could show “interesting” results across VI/PI/Q-learning. VI/PI showed different solutions and it turns out that certain conditions for bellman equations is not true, and hence the solution is different and I explained why.
For this assignment, I wrote significantly more custom code for A4 as compared to A2 such as:
- Reward Shaping
- Returning steps/iterations/delta for VI/PI/QL
- Tracking of Q in VI/PI, visited states in QL etc.
Final exam
The final exam consist of 57 questions, with 19 questions each from SL,UL and RL. Personally I used notes from:
It turns out that my hypothesis was correct - As the assignments covered SL1-6, UL1-2, and RL1-2, the finals mainly focused from SL7-10, UL3-4, RL3-4. There were a higher number of questions on bayesian, information theory, feature selection / Transformation and game theory.
Looks like you have no escape!
Conclusion
Personally, I feel that coding the algorithms is also important as it gives you a good solid foundation on understanding how the algorithm worked and gives you better intuition - but the TAs somewhat “brush” this off as saying that in actual work, you just call APIs, and understanding the results matters more.
Since the TAs talk about “actual work”, I would have preferred if they included things like normal optimization problems such as linear programming, power analysis, type I vs type II errors, bayesian network, as this also branches out to RL.
To repeat, the amount of anxiety&stress generated by this course is not trivial, and unfortunately it is one of the core requirements for the machine learning specialization ![]() .
.