CS7650 OMSCS - Natural Language Processing
Overall Review
I took NLP during summer 2024, and overall, the content (lectures) are great, Dr Mark Riedl did a good job in explaining various concepts from RNN, to LSTM and Transformers. It go through the various intuitions of certain neural architectures such as word2vec, embeddings and various use cases / challenges of various tasks, such as translations, language generation, privacy, etc.
There are two noteworthy mentions you should know if you are deciding whether to take this course:
- If you already took deep learning then this course may be marginal additional knowledge.
- The first few lectures/assignments will mostly be “free”, as they are covering the basics of neural networks, pytorch which you will already have done in DL.
- There are lectures conducted by Meta Employees (similar to DL), which can be challenging to comprehend sometimes.
- Otherwise, NLP seems like a good course to ramp up for DL - although with how things are at the moment, enrollment for this course will be a challenge, unless you are comfortable with taking DL in your 7/8 course. Plan your courses carefully!
- I share the sentiments that the assignments can be better / more challenging. If you are considering taking this course to learn more about LLMs, such as how chatGPT is built (or other state of the art NLP models), then this course might not be for you.
- The professor (Dr Mark Riedl) also addresses in Ed (in my semester), to quote:
This course sets up a progression that will help you understand how we got to the point of large language models. We dive pretty quickly into neural approaches to natural language processing. You will understand how neural approaches to language models work, and practice setting up and training language models.
But there is so much more to NLP than just large language models! And we will cover practical, real world stuff that doesn’t get 100% of the hype cycle.
That being said, there are still useful things to learn, and I was looking for an easy semester, combined with the fact that this course has a historical rate of > 80% of students getting an A.
Time requirements
The time requirements are pretty chill, other than the last assignment and final exams, I spent less than 10 hours a week. Overall a nice summer course.
A fair “warning”, this course is “back-loaded” - or maybe it is because I took it in the summer, the last project and final exam requires significantly more time so, do not be fooled or complacent!
Even so, it is still wayyyyy less stressful (No honorlock, open everything, less complexity) as compared to other courses like ML, DL, or GIOS.
Lectures
There are a total of 14 modules and they are listed below:
| Module 1 | Introduction to NLP |
| Module 2 | Foundations |
| Module 3 | Classification |
| Module 4 | Language Modeling |
| Module 5 | Semantics |
| Module 6 | Modern Neural Architectures |
| Module 7 | Information Retrieval (Meta AI) |
| Module 8 | Task-Oriented Dialogue (Meta AI) |
| Module 9 | Applications Summarization (Meta AI) |
| Module 10 | Machine Reading |
| Module 11 | Open-Domain Question Answering (Meta AI) |
| Module 12 | Machine Translation |
| Module 13 | Privacy-Preserving NLP (Meta AI) |
| Module 14 | Responsible AI |
Additional Resources
Grades Distribution
The quizzes accounts for 10%, mid terms 10%, finals 10% while the assignments accounts for 70%. There are a total of 6 assignments (1, 2, 3A, 3B, 4, 5), the first 5 assignments accounting for 10% each and last assignment accounting for 20%.
Quizzes
Quizzes are pretty chill and open everything - You get 2 attempts and the highest score is taken.
Assignments
The assignments are all done in notebooks and the instructors suggested using colab. Personally I did everything locally with my M1 Mac book pro with mps, which worked pretty well for all of the assignments. This also worked well for me as I like to use github to backup / version control my assignments.
During my semester, there is no office hours for the assignments. Instead, recitation videos from a previous semester and I only watched them for Hw4 and Hw5, and especially useful for Hw5. (Read on to understand why I watch the recitation starting from hw4). For some bizarre reasons, the TA team decided to release these pre-recorded videos 1 week after the assignment is released, which I have no idea why; They always asks us to start early but at the same time hold back information? Hopefully this will change in the future.
Personally I am not a fan of jupyter notebooks, and for the last assignment I moved it out to python scripts before transferring it back to the notebook.
Also, the test cases can be a little “flaky” or too simplistic - Even though you could pass the test cases, it might not work for the next section or the next set of test cases.
- In times like this, I find it easier to just look at the test suite, break it apart and debug from there.
For the first 5 assignments, test suites / Gradescope is provided, and to my best knowledge there are no hidden tests. The lower quartile for the first 5 assignments is ![]() .
.
Assignment 1 - Introduction to Neural Networks with PyTorch
This assignment basically tries to onboard you to the basics of Neural Networks and Pytorch, such as:
- Getting your environment set up
- How to prepare your data with neural network (batches / data loader)
- Creating a simple network with PyTorch
- Plot out the computation graph
- Perform training loop which includes things like optimizer, loss function etc.
- Evaluation (of a basic end to end ML pipeline)
Assignment 2 - Text Classification
This assignment gets you to implement basic text classification with the following models:
- Naive bayes
- Logistic regression using bag of words (BoW)
- Moving from Logistic (binary) to Multinomial (multiple classification)
Assignment 3a - Language Models Part A
The assignment now moves beyond your simple neural networks, and touches on Recurrent Neural Networks (RNN)
- RNN model - You need to do this with the basic PyTorch layers, and not simply
torch.nn.RNN - Representing words as tokens (or vectors)
- Adjusting certain network architectures to prevent local optima.
- Such as sampling from the top N outputs instead of argmax.
- And using temperature to balance exploration versus exploitation.
This is probably a known knowledge for folks who did DL - In PyTorch when computing log-loss cross entropy, it also performs softmax. So when using the loss criterion, the input is the logits and not the probability.
Assignemnt 3b - Language Models Part B
This assignment is probably a significant step up from the previous one - requiring you to implement LSTM and LSTM with an attention mechanism.
- LSTM - Again, with basic PyTorch layers.
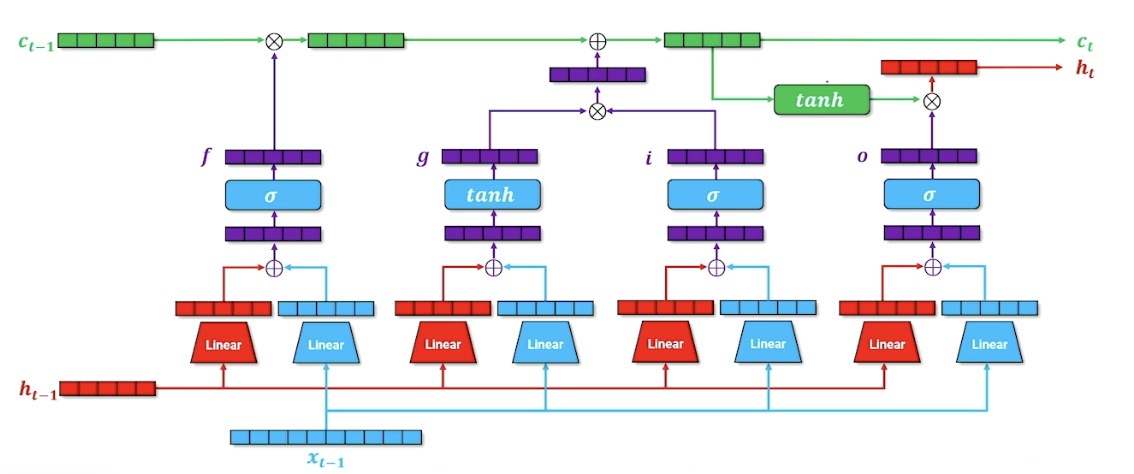
- LSTM with an attention mechanism
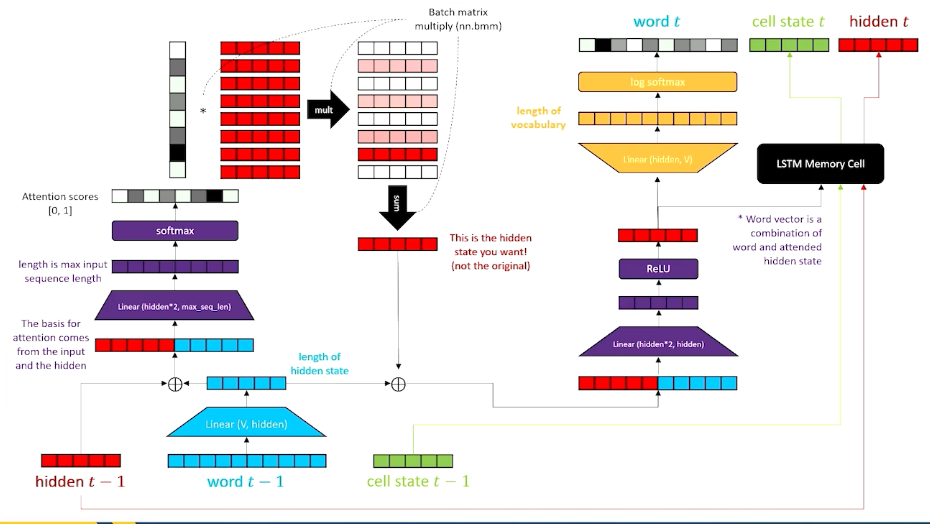 There is a typo with the above image, refer to the notes for more information
There is a typo with the above image, refer to the notes for more information
This assignment took me significantly longer, as I was implementing my attention mechanism based on the information above which I missed out on an errata that was pointed out in the lectures ![]() . Hence, starting from Hw4 I decided to simply wait for the recitation before attempting the assignment.
. Hence, starting from Hw4 I decided to simply wait for the recitation before attempting the assignment.
Assignment 4 - Distributional semantics
This assignment moves on to other neural network architectures, such as Word2Vec.
- Skip-Gram model
- Continuous bag of words model (CBOW)
- Using pre-trained word2vec models such as GloVe and use it to retrieve top k words/documents.
Assignment 5 - Mini-Project
In the last assignment, the final goal of project is to build a retrieval system that is able to answer questions in natural text. For example:
1
2
3
4
5
6
7
8
9
ans = get_prediction("When was Alexander Hamilton born?")
print(ans)
# 11 january 1755
ans = get_prediction("Who is Steve Beshear predecessor?")
print(ans)
# ernie fletcher martha layne collins robert stephens
To do this, you will need to do quite a couple of things. In a nutshell:
- You need to prepare your training data in (question, key, value) tuples
- Prepare some form of vector store
- Train your model
- Figure out a way to extract named entities from natural text questions
- Get prediction.
Watching the recitation is highly recommended!!!
The TAs narrowed down the scope of the final project that is not stated in the notebook, such as:
- Letting us know that train/set can be as little as 500/100 respectively which dramatically reduced pre-processing time and memory/compute usage.
- Along with some “hacks” (imho feature leaks) to make training goes faster given limitations on our computational resources.
There is no autograder or any test suites to tell you if you are on the right track. In terms of grades, the lower quartile is 40/45, while median is 43/50.
Mid terms
For my semester, the mid terms is being replaced by a paper review. The instructors provided 6 questions (2 points each), and each question can be answered with less than 300 words. In my semester there are two options
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
The grading seems to be very generous and the TAs are not out to get you - the lower quartile is 10/12, and median 11.5/12.
Finals
The final exam is a open everything, open ended which consists of 11 questions (with 1 question worth 2 points).
In summary (as well as respecting the honor code), the questions covers a range of topics, from system/ml design, to debugging models (what are potential reasons model X is behaving this way?) as well as some calculations.
Similar with the midterm, the grading also seems to be generous, the lower quartile is 9.5/12, and median 10.75/12.
Assuming you got lower quartile for everything (with 80% for quizzes), your final score will still be 92 - making it a relatively easy course. Things might change in the future though ![]()
Conclusion
By far, the lectures by Dr Mark Riedl are great - probably the best lectures I had so far in OMSCS! Given that I have taken DL, it made this course significantly easier for me. My overall recommendation for this course is if you have taken deep learning, feel free to skip this course unless you want something easy or use this course to pair up. Otherwise, it is probably a good introduction to quite a few things, especially if you are new to jupyter notebooks, Python, Pytorch, Neural Networks, and serves as preparation for future courses.